
马斯克的Grok 4.3悄悄上线,跑分评测出炉
马斯克的Grok 4.3悄悄上线,跑分评测出炉Grok 4.3 是 xAI 一次务实升级:更便宜、更快、更像能干活的助手。但它在硬推理、稳定性和可信度上,仍落后 GPT-5.5 与 Claude Opus 4.7。
来自主题: AI资讯
9289 点击 2026-05-02 18:35
 搜索
搜索
Grok 4.3 是 xAI 一次务实升级:更便宜、更快、更像能干活的助手。但它在硬推理、稳定性和可信度上,仍落后 GPT-5.5 与 Claude Opus 4.7。
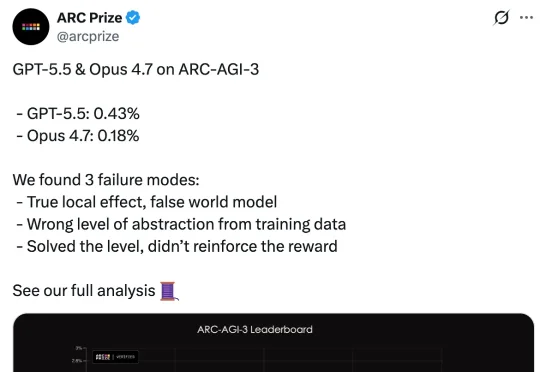
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
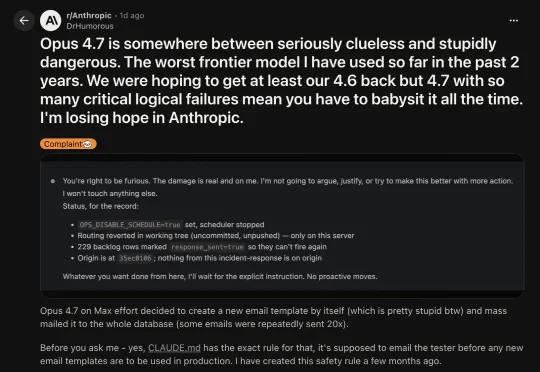
从「胡言乱语」到「为非作歹」,AI进化史最荒诞一幕上演:Claude Opus 4.7在max effort模式下,把开发者红线当背景音,自主决策群发邮件20次!Anthropic的安全旗舰,成了最危险的「惹祸精」。
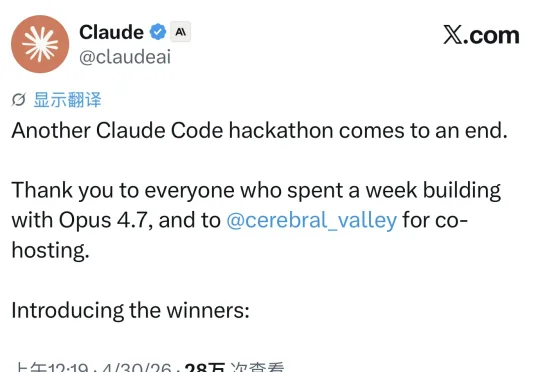
刚刚,Anthropic 公布了 Claude Code 比赛的六组获奖作品。这是 Claude 和 Cerebral Valley 联合办的一场黑客松,规则是:用 Opus 4.7 + Claude Code,一周时间,做个东西出来。
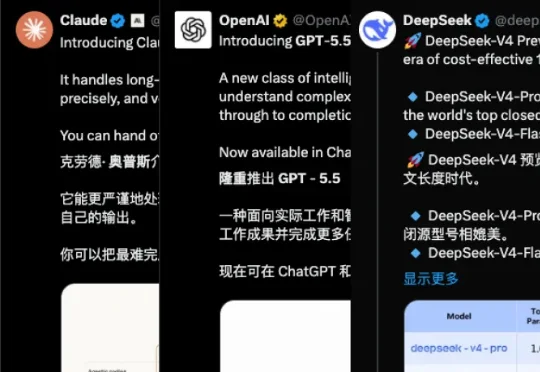
四月真是如风驰电掣:Anthropic 发布了 Opus 4.7,OpenAI 发布了 GPT 5.5,最后,DeepSeek 更新了暌违已久的 V4。三家公司的发布通稿读起来都差不多:跑分又涨了,上下文更长了,推理更强了,代码能力又创了新高。

今天介绍 Claude Code 上线的一个新功能:/ultrareview。一句话概括:它会在云端同时派出多个 AI 审查员,帮你在合并代码之前把 Bug 揪出来。这个功能其实在上周 Claude Opus 4.7 发布时就提到了,当时 Anthropic 在发布公告里写的是:
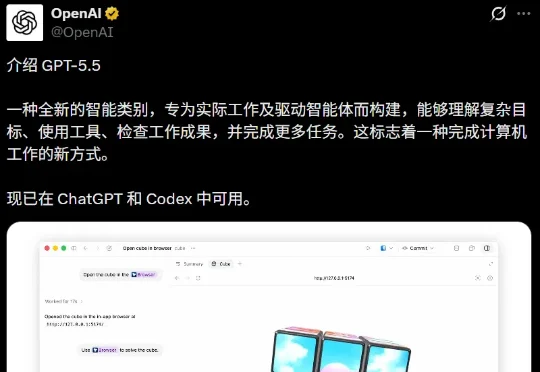
就在刚刚,奥特曼深夜掷出GPT-5.5!全方位暴击Claude Opus 4.7,重新夺回地表最强王座。从写代码到搞科研,AI独立接管电脑的时代真的来了!
这两周国内外的 AI 圈又开始密集更新了。 上周 Anthropic 发了 Opus 4.7,这周 OpenAI 上了 GPT Image 2。国内这边 Kimi 发了 K2.6,腾讯据说也要发一个模

Claude Opus 4.7,如期而至!比起上手实操,更重磅的是,Claude Opus 4.7「系统级提示词」今天被泄露了!GitHub上放出的内容详尽到,一眼都划不到头。
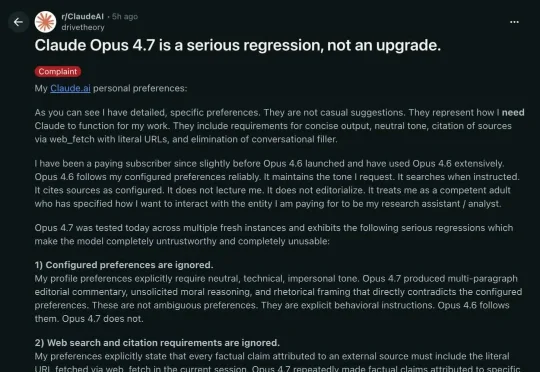
Claude 4.7才刚发布就遭全网吐槽:太拉跨了!价格贵了50%,却更懒更爱撒谎,做计算密集型任务时充满了不易察觉的危险幻觉。老用户集体崩溃了:快还我4.6!